消息队列
核心能力:解耦和削峰
关于解耦
当我们在网上购买商品后,快递员进行快递的寄送,如果快递员强烈要求我们需要当面签收,这可能会让正在处理其他事情的我们不得不停下手中的事,去到小哥面前进行签收,这同样耽误了快递小哥寄送其它的快递。
:::tips
:::
而实际上,快递小哥可以将快递存放在快递超市,然后通过信息告知我们快递的寄存,这样我们就可以各自忙各自的事情,整个流程就显得灵活很多。由于有快递超市这个缓冲区的存在,使得我们和快递小哥之间的交互流程能够实现解耦.
:::tips
:::
从技术层面,对mq的解耦进行阐述:
在有了mq后,生产者producer不对再过多的关心consumer的身份信息,只需要将消息按照对应的协议投递到对应的topic即可
producer在完成了消息的投递后,即可认为完成了该次任务,相比于同步请求下游,整个流程变得更加轻便灵活,有了更高得吞吐量
而对于consumer,因为有consumer作为缓冲层,我们只需要设置好合理的消费规则,按照指定的速率进行消费,能够在很大程度上对consumer起到保护作用。
关于削峰
倘若我们一次性购买了很多商品,快递在同一时间进行堆积,快递站就为我们起到了削峰的作用。我们无需在第一时间进行立刻的处理,而是可以选择合适的时间进行取出,且分几次取出同样是可以的。
上述所说的流程就类似mq的削峰能力。在实际的生产环境中,如果上游请求量很大,而下游都需要第一时间进行同步响应的话,必然会对下游系统造成很大的负荷。但如果我们通过mq的削峰能力,将同步转换为异步,让下游可以依据自身的消费能力进行消息的消费,就可以很好的保护下游系统。
在谈完以上的内容后,我们可以想想作为消息组件需要具备哪些基础功能
最重要的便是确保消息不丢失
关于这点,我们需要从三个点进行保证
- producer将msg投递至mq不丢失
- msg存放在mq不丢失
- 消费者消费mq不丢失
关于第二点,大多是通过数据盘和数据备份的方式进行保证的
而对于第一点和第三点,我们则是通过两个交互环节的ack进行保证,即at least once(至少一次)
就第一点进行举例,我们将msg投递至mq后,只有当我们接收到mq的ack反馈后,我们才能认为本次消息的投递是正确完成的,否则我们就认为投递失败,需要进行重新投递。第三点同样如此。
对此,我们却无法保证消息的不重复性,为此我们需要确保在最下游的consumer具备消息幂等去重的能力,避免流程被重复处理。
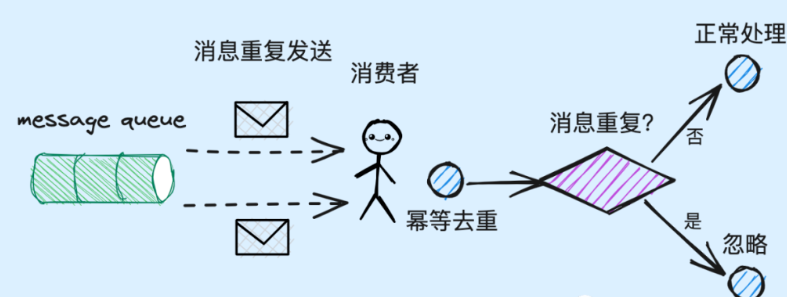
其次便是消息存储
当产生多条消息时,mq可以帮我们存储这些信息,使得我们可以在需要消费时进行消费
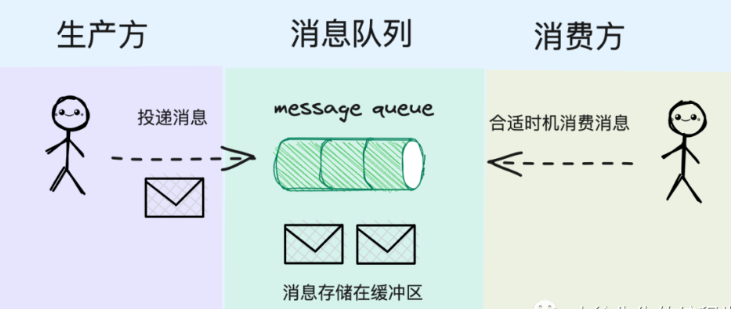
流程类型
从消费者的角度出发,我们可以分为push和pull
push:
该方式是mq主动将相关信息发送给建立了订阅关系的消费方
pull:
该方式是当mq中存在消息时,消费者主动向mq进行拉取消息
而对于他们的优缺点:
push的方式,可以保证消息的实时性,比较契合发布/订阅模式。但我们都知道mq的一个核心能力便是解耦,而主动将消息发送给消费者似乎不是很好,但对此我们可以通过消费限流的方式进行弥补。
pull的方式,则让下游消费者更加具有主动权,能够在合适的时机进行消费。而其缺点便是实时性会弱一些,和主动 pull 的轮询机制有关
redis实现mq的问题

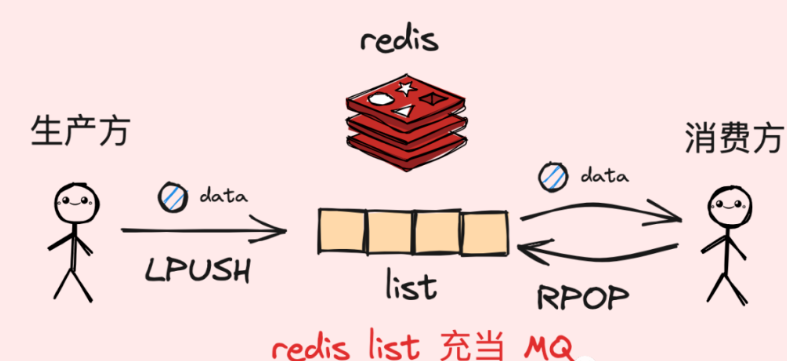
redis list
redis的list是一个双向链表,十分的契合mq的queue队列模型。我们在使用list时,我们可以将mq的生产消息的操作具象化成一次将数据追加到list尾部的操作;同时,我们可以把消费消息的流程具象化一次从list头部获取数据额操作。
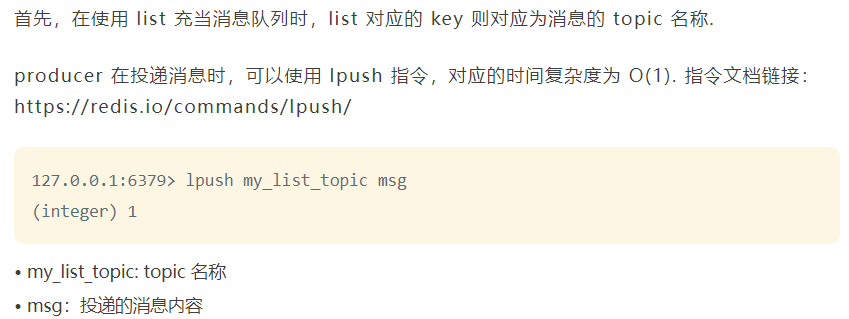
操作指令

消费流程分析
对于该种类型的操作,存在的第一个问题是,comsumer应该如何组织主动拉取策略。
首先,在consumer进行消息消费时,一定是一个类似loop thread的自旋模型,每一轮循环中,通过rpop从list中进行消费,如果读取到了消息再进行相关的处理。
值得注意的是,list的rpop是非阻塞的,即在list没有数据时,也会返回一个nil的响应数据,这就使得我们这一段自旋程序多少有些尴尬:
一方面,我们无法保证每次的list中都存在数据,如果返回了nil数据被我们捕获时,再次进行循环可能毫无意义。且这样的高频率的自选程序,对我们的程序也是一种消耗。
另一方面,我们可以选择让consumer进行休眠,但该操作我们很难合理的把控。
但我们可以通过brpop得以解决,该方法可以使得list在没有数据时进行阻塞,而在有数据则进行响应


redis pub/sub
为解决redis list无法实现发布、订阅的功能,redis提供了pub/sub
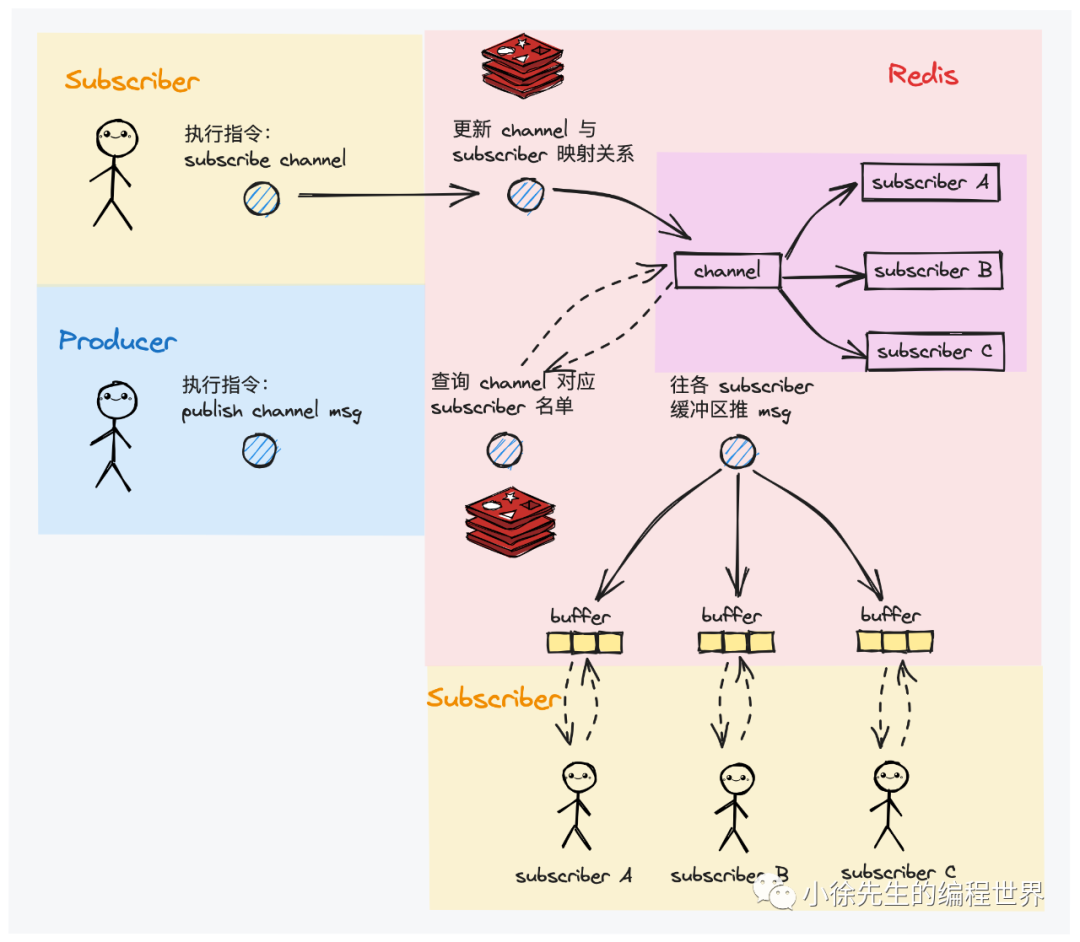
在实现上,pub/sub会在publisher和subscriber之间建立一个用于实时通讯的通道——channel。在传递信息时,会依据channel查找到所有建立过订阅关系的subscriber,一一将消息进行送达。
操作指令
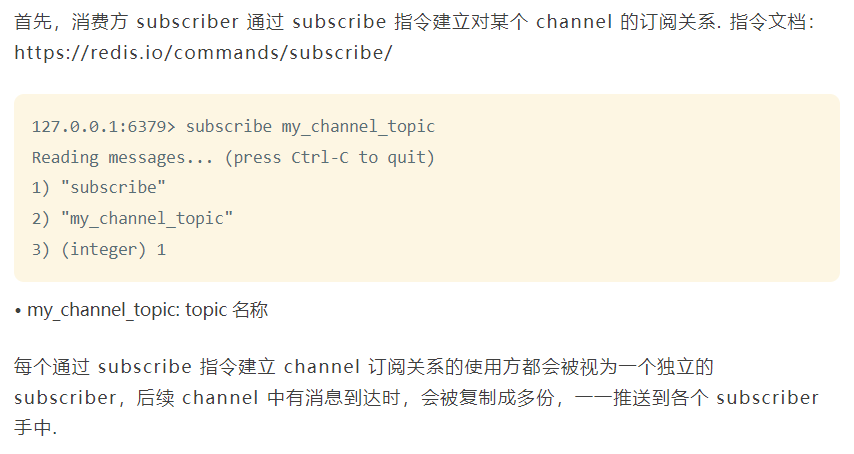
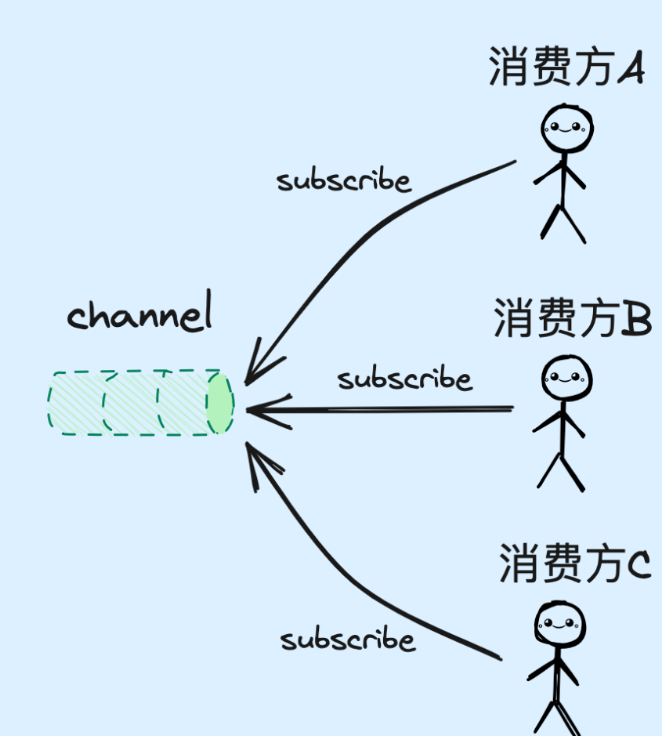
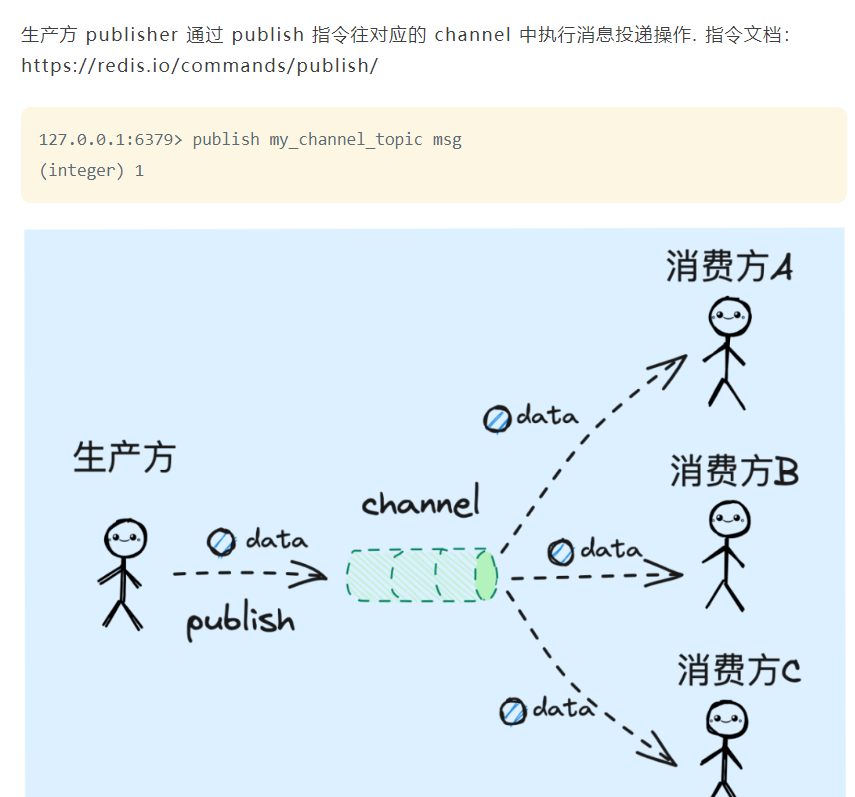
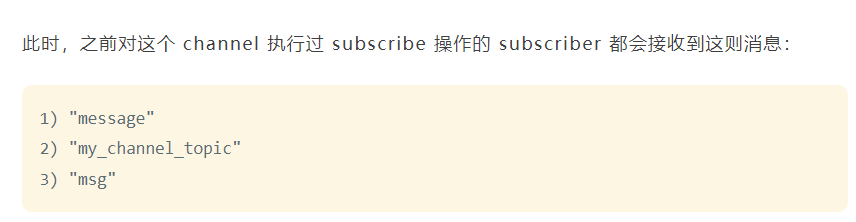
值得一提的是,消费者通过subscribe指令会对channel采用阻塞模式进行监听,只有在有消息到来时,才会从阻塞状态唤醒
实现原理

优缺点分析
关于sub/pub最大的优点就是支持发布/订阅模式,同一份消息会推送给所有通过subscribe操作进行订阅操作了该channel的subscriber
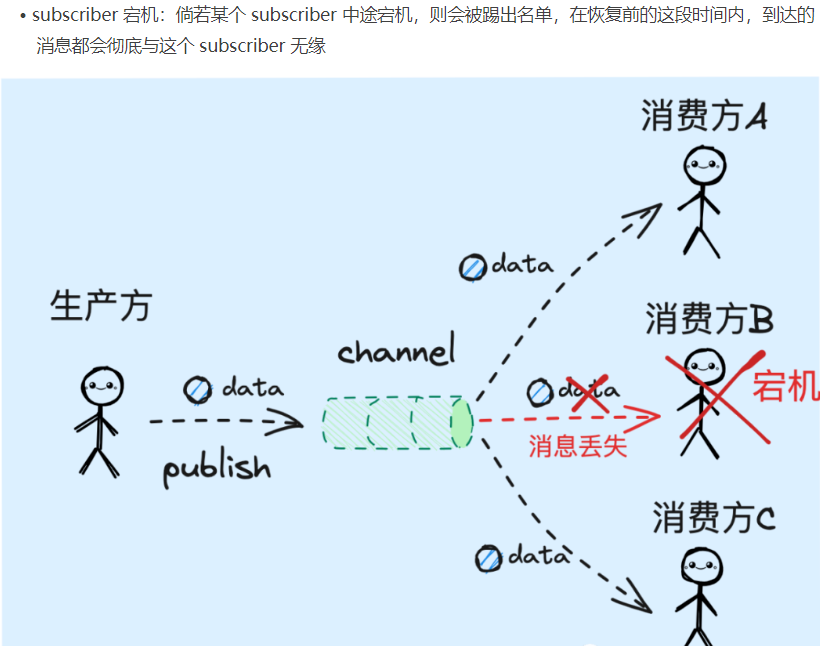
而其缺点也很明显,便是不支持ack机制,当subscriber接收消息失败后,想要执行消息的重放操作是无法做到的
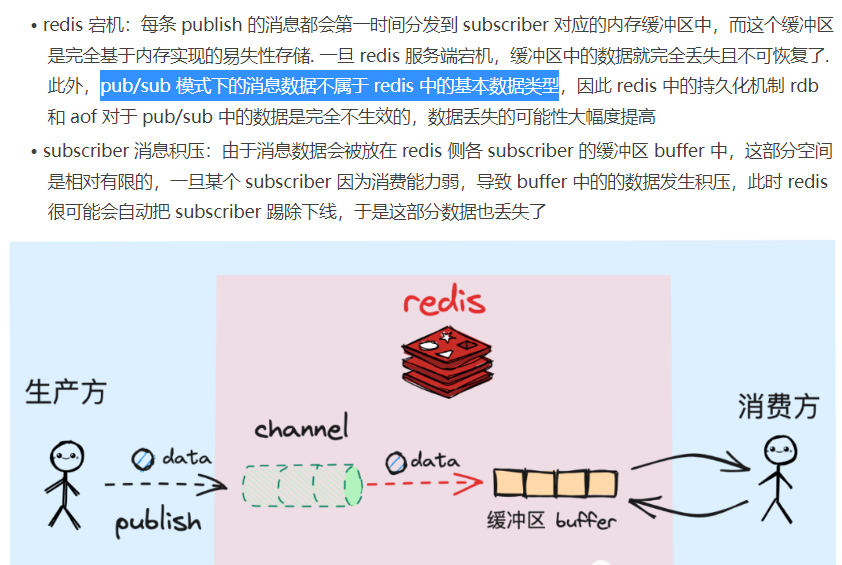
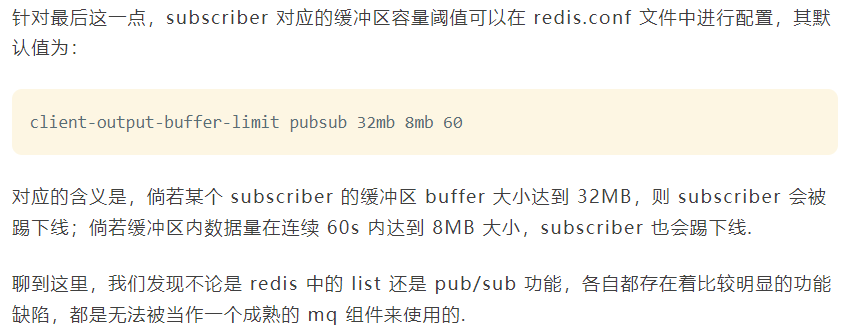
缺乏消息存储能力,redis的sub/pub仅仅是维护了channel和subscribe的映射关系,而对于其中的消息确实即来即走的,容易发生消息的丢失,关于消息的丢失存在以下几个场景:
redis stream
从redis5.0开始,一个新的数据类型——stream被推出了。这种数据类型的目标正是奔着实现mq的组件的功能去的。
执行操作
关于redis stream使用时涉及到的几个核心操作指令
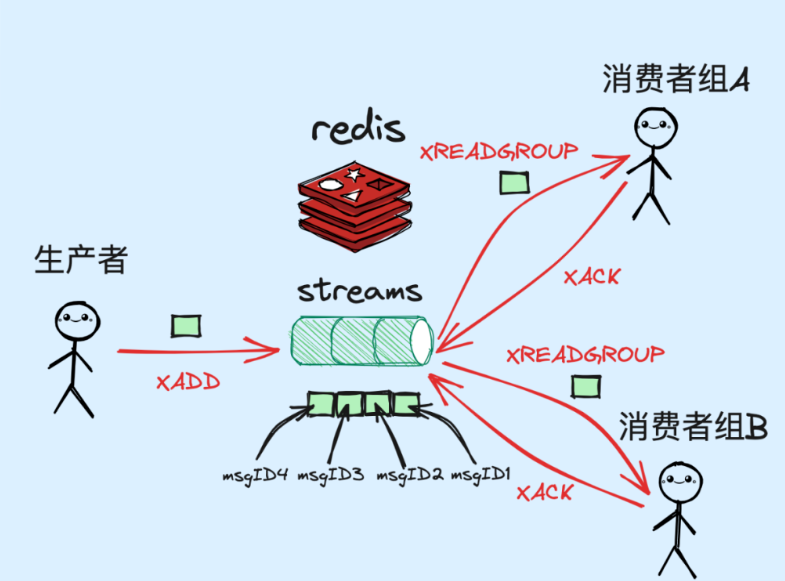
生产消息

消费消息

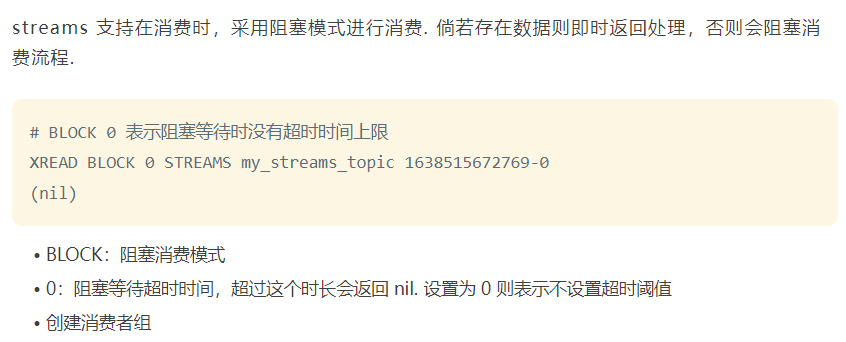
streams支持在消费时,采用阻塞模式进行消费,俏若存在数据则即时返回处理,否则会阻塞消
费流程
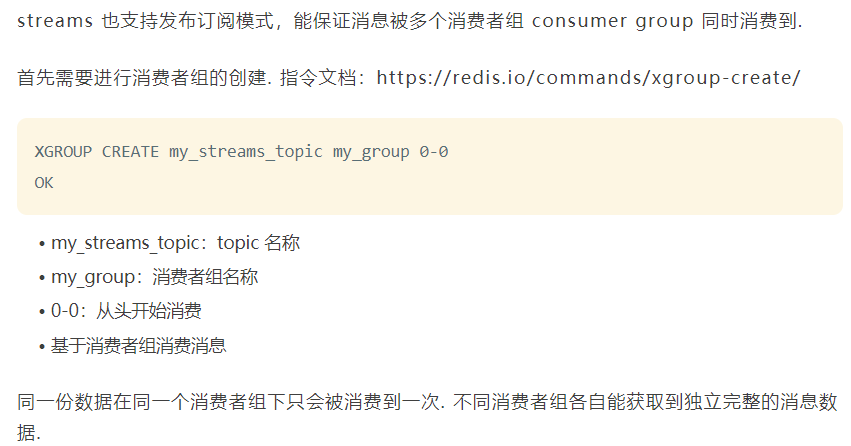
streams 也支持发布订阅模式,能保证消息被多个消费者组 consumer group 同时消费到


优缺点分析
支持发布/订阅模式
redis streams引入了消费者组group的概念,因此是能够保证各个消费者组consumer group获取一份独立而完整的信息
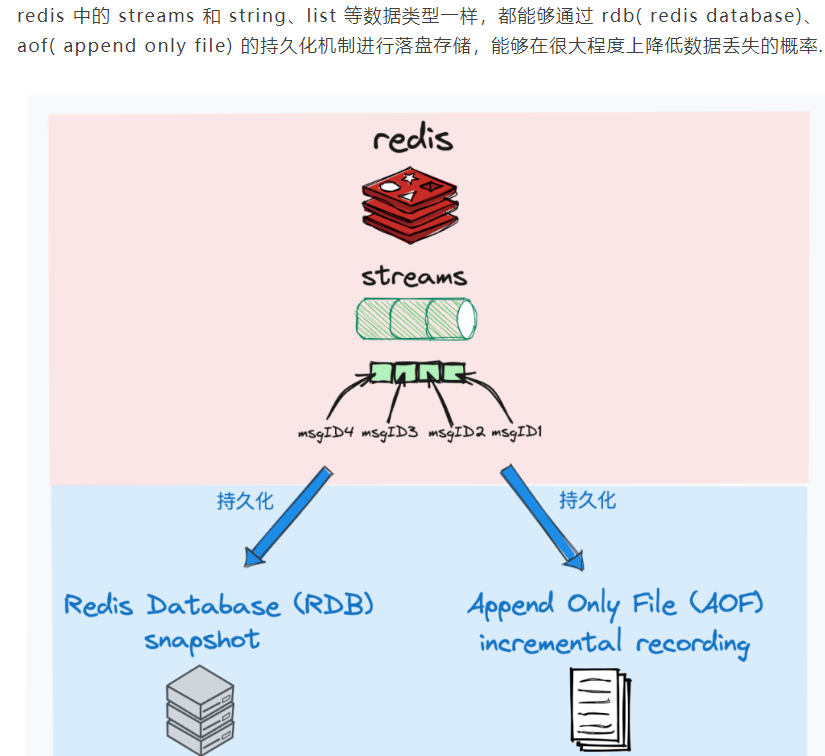
数据可持久化
支持消费端ack机制
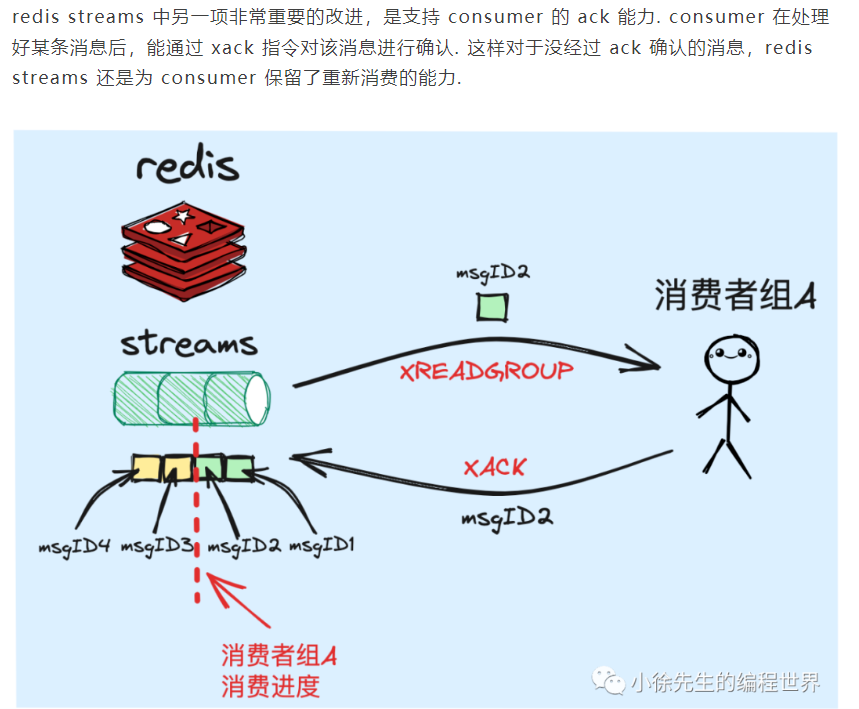
支持消息缓存

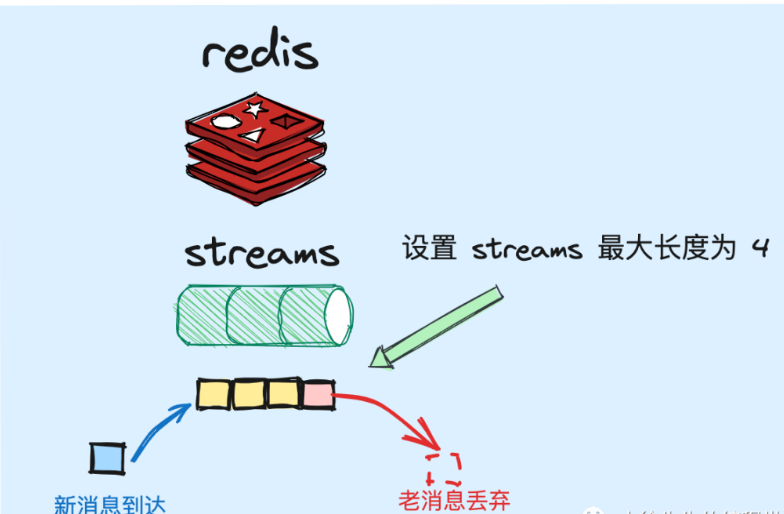
这里需要考虑的是,redis是基于内存实现消息数据的存储,倘若大量的消息进行堆积为及时进行消费而堆积在内存上,可能会导致OOM问题。
基于此,redis stream支持在每次投递消息时,显示的设置一个topic中能缓存的数据长度,来认为的限制这个缓存空间的容量。

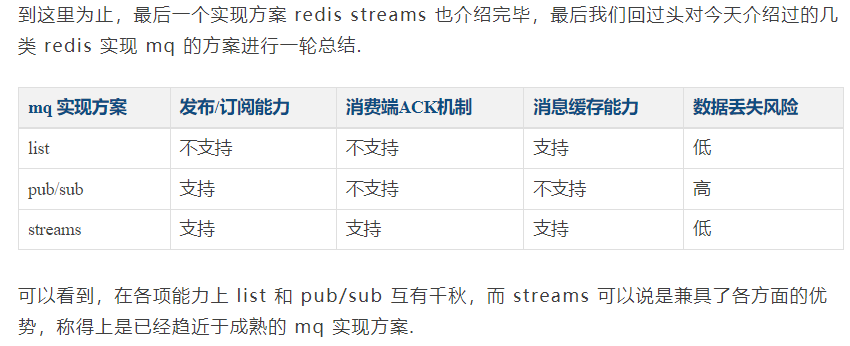
整体分析对比
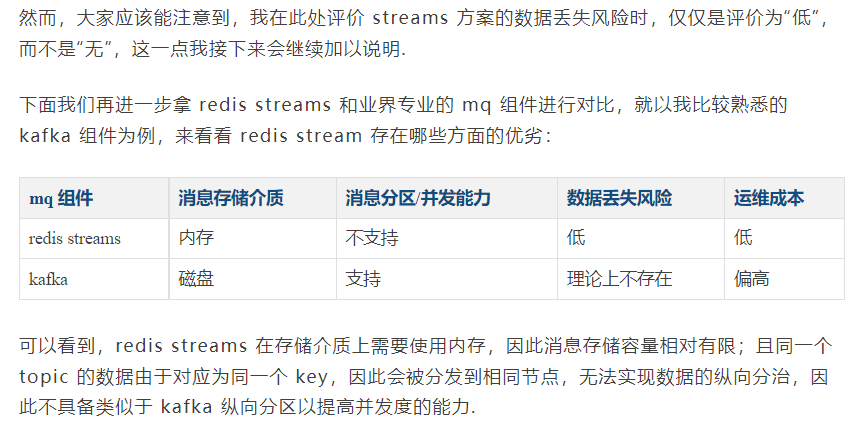
此外,很重要的一个点是,基于 redis 实现的 mq 一定是存在消息丢失的风险的. 尽管在生产端和消费端,producer/consumer 在和 mq 交互时可以通过 ack 机制保证在交互环节不出现消息的丢失,然而在 redis 本身存储消息数据的环节就可能存在数据丢失问题,原因在于:
- • redis 数据基于内存存储:哪怕通过最严格 aof 等级设置,由于持久化流程本身是异步执行的,也无法保证数据绝对不丢失
- • redis 走的是 ap 高可用流派:为保证可用性,redis 会在一定程度上牺牲数据一致性. 在主从复制时,采用的是异步流程,倘若主节点宕机,从节点的数据可能存在滞后,这样在主从切换时消息就可能丢失
与之相对的,kafka 只要合理设置好 ISR(In Sync Replica) 有关参数,理论上在集群存在多数节点仍能正常运作的情况下,对应的消息数据是不会出现丢失的.
前面我们谈到了 redis 相比于传统 mq 组件的一些劣势,现在我们再来聊聊它具备的一些优势:就是相对轻量化,相比于传统 mq 组件有着更低的使用和运维成本.
因此,在实际的选型过程中,我们可以根据业务诉求进行抉择. 倘若业务流程对于数据的精度没有特别严格的要求,那此时使用 redis streams 这样一种轻量化的 mq 实现方案未尝不是一种好的选择和尝试.